Right now, every thought leader and influencer on the internet (particularly LinkedIn) is telling finance teams to use AI. Your (correct) first thought would then be: What do they mean by ‘AI’? It’s an amorphous term, and you can’t just go off piste implementing all sorts of tools into your workflow.
Finance teams handle commercially sensitive data, personal information, and numbers that need to be auditable, so the GDPR, cybersecurity, and data governance stakes are higher than in most other departments. You’re the financial heartbeat of the organisation after all.
This article will help you understand what AI tools for finance are, what they aren’t, and the costs and benefits of the various options available.
Embedded AI: tools that learn from your data
This is AI that lives inside your existing software and gets better the more you use it. That’s it in a nutshell.
Take our own AI-enabled auto-categorisation feature. When you upload a receipt, the system reads the text, converts it into a clean digital record, and then compares it against your previous receipts to identify patterns.
Based on those patterns, it suggests the most appropriate expense category. If its confidence in that suggestion is high enough, it fills the field automatically. If not, it leaves it empty for you to complete.
The key point here is that the model is working from your data only (it never draws on data from other companies). It is not a generic system trained on data from thousands of unrelated sources and then applied to your receipts.
It’ll get better at recognising what your team spends on, how you categorise things, and gets more accurate over time as your receipt history grows.
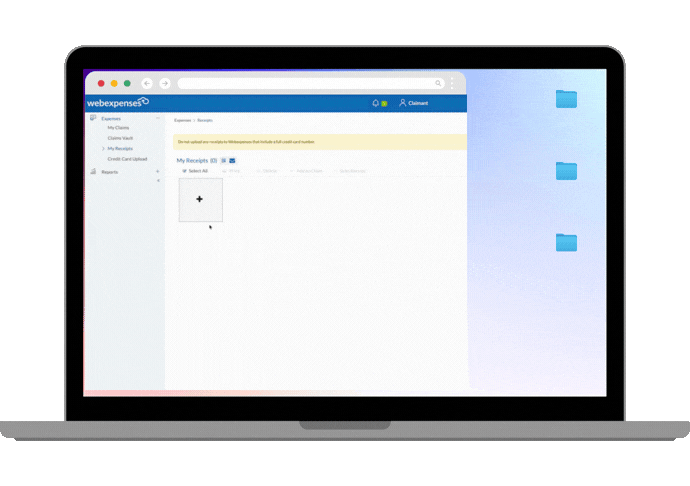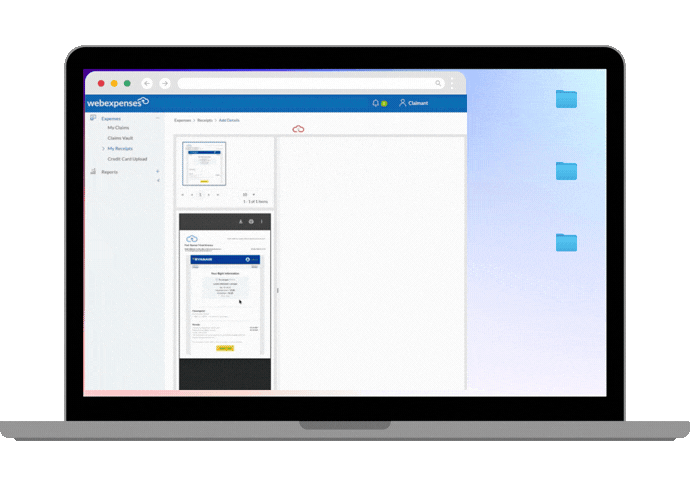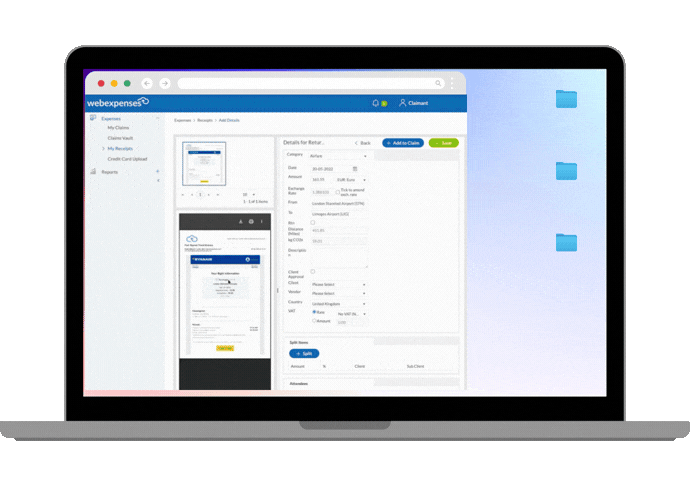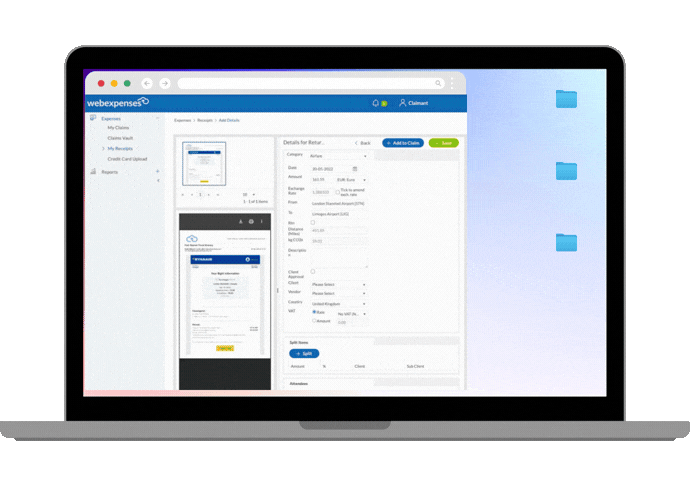
This kind of AI is generally lower risk from a data governance perspective, because the data used to train and improve the model is yours, stays within the platform, and does not leave your Webexpenses ecosystem to train models serving other organisations. It also tends to be more accurate for your specific use case, precisely because it is specific.
AI tools for finance that operate this way are often the most practical starting point, because the adaption happens in the background and the output is actionable within your existing workflow.
AI assistants: on-demand support without the wait
If you use any SaaS service, you’ve likely encountered a conversational AI assistant. The AI chatbot (a good one at least) is designed not to automate a process or replace human advisers, but to answer questions and resolve queries in real time.
WADE is Webexpenses’ AI assistant. We have teams in both the UK and Australia, which means you can speak to a real person at almost any hour of the day. But for those rare moments when your team runs into an issue outside of even our combined working hours, a Sunday evening perhaps, WADE is available immediately to triage the problem.
It can answer support queries, guide users through common tasks, and, if it cannot resolve something, flag it for a member of the human team to pick up as soon as they are back online.
This kind of assistant is well suited to handling repetitive, process-level questions at scale. It does not replace a knowledgeable human, but it removes the friction that builds up when people cannot get fast answers to straightforward problems.
General-purpose LLMs: useful, but read the small print
Tools like ChatGPT, Claude, Gemini, and others are what most people mean when they talk about “AI” in casual conversation. They are large language models trained on vast amounts of text data, capable of drafting documents, summarising information, answering questions, writing code, building apps and according to certain trillionaires, causing human extinction.
For finance teams, there are legitimate and productive uses for these tools: drafting communications, summarising reports, and stress-testing the logic of a business case. Many finance professionals are already using them for exactly this kind of work.
But there are real compliance risks that you need to understand before you start.
The main one is data privacy and GDPR. When you type something into a general-purpose LLM, that input may be used to train the model. Different providers have different policies on this, and those policies change.
If you paste in commercially sensitive data, personally identifiable information (PII), salary figures, supplier contract terms, or anything else that your organisation has a duty to protect, you may be sharing it in a way that falls outside your data protection obligations.
This does not mean these tools are off-limits. Most major platforms let you opt out of model training in your account settings, and that is worth doing as a baseline step. But it is also worth knowing what you are taking on trust when you do. Toggling the setting basically amounts to ‘trust me, bro’ — the protection is only as good as the provider’s word, and those policies change.
Most enterprise tiers of these platforms offer options to prevent your inputs from being used for training. But the default settings are not always conservative, and most organisations have not yet established clear policies about what their teams can and cannot share.
It is also worth knowing that the protection is not always absolute. Even on tiers that promise not to train on your inputs, some providers have used signals like thumbs up or thumbs down feedback on a response in other ways. The small print is worth reading more than once.
A useful rule of thumb: if you would not post it in a public Slack channel, do not put it in a general-purpose LLM without checking your organisation’s data handling policy first.
Local LLMs: more control, more complexity
A local LLM refers to a model that runs on your own hardware or on servers within your organisation’s own infrastructure, rather than in the cloud.
Tools like Ollama, llama.cpp, and LM Studio let you run open-source models such as Llama (Meta’s open-source model family) or Mistral locally. ‘Locally’ just means data processed by the model never leaves your environment.
For finance teams handling sensitive data, this is an appealing idea. If the model is running on your own servers, you do not have the same concerns about inputs being transmitted to a third party or used for external training. You retain full control of the data.
The practical barriers depend on what you need. Running a capable model locally on a personal device is more achievable than it used to be.
At an individual level, the barrier is low, particularly with newer machines built around unified memory. Apple’s Mac Studio and some of the newer mini PCs share memory between the CPU and GPU rather than relying on a separate graphics card, which lets them run larger models reasonably well without dedicated GPU hardware.
At organisational scale, it is a different question. If you want multiple users querying the same model, handling large financial documents reliably, or performance that competes with the frontier cloud models, you are looking at serious GPU infrastructure and ongoing technical resource to maintain and update it.
If you work in a regulated environment, in banking, insurance, or any sector with strict data residency requirements, a local LLM is worth serious consideration. It is not a free pass on security either; you still need to think about how that environment is secured, the same as you would for any other system holding sensitive data.
For most finance teams in SMEs, the overhead is likely prohibitive for now. The more practical near-term move is to use enterprise-tier versions of cloud-based tools with appropriate privacy controls enabled, while keeping an eye on how local model capability develops.
A related development worth knowing about is small language models (SLMs). These are scaled-down models, like Microsoft’s Phi series or Google’s Gemma, designed to run efficiently on limited hardware while performing well on focused tasks.
The logic is that a smaller model trained or fine-tuned on a specific domain, accounting standards, tax rules, financial reporting, can outperform a much larger general-purpose model on that narrow task, at a fraction of the computational cost.
For finance teams, this is worth watching. Purpose-built SLMs for finance are still emerging, but the direction of travel is clear.
AI agents: beyond question and answer
Most of the AI tools covered so far generate text in response to a prompt. AI agents are different. They’re systems designed to take actions: querying databases, executing workflows, browsing for information, triggering processes in other software.
Rather than answering a question, an agent can be given a goal and left to work out the steps.
In finance, the practical applications are beginning to take shape. Agentic systems are being used to automate accounts payable workflows, reconcile transactions across systems, and monitor spend against policy in real time without human prompts at each step. The appeal is obvious: less manual intervention, faster processing, fewer errors from rekeying.
The risks are also real. An agent that can take actions can also take the wrong ones. In financial processes where accuracy and auditability are non-negotiable, the question of how you verify what an agent did, and why, matters enormously. As Sage’s CEO Steve Hare argued, you cannot outsource personal accountability in finance, whether to a human or a machine.
At Amazon, for example, AI agents have been implicated in costly failures that are hard to dismiss as edge cases. In early 2026, the company’s internal documents revealed that AI coding tools contributed to catastrophic outages at Amazon that caused millions of customer orders to go missing or fail to process:
- On 2 March, AI tools incorrectly processed delivery data, leading to around 120,000 lost orders.
- On 5 March, an AI-assisted configuration change crashed the retail site entirely, causing a 99% drop in orders across North American marketplaces and an estimated 6.3 million lost orders.
The root cause in both cases was the same: rapid, automated configuration changes with insufficient human validation and no meaningful guardrails on the scale of potential damage. Amazon subsequently implemented a 90-day safety reset, mandating two-person review for any code changes (safeguards that, in hindsight, should have been there from the start).
That is not a cautionary tale about a niche edge case. It is a demonstration of what happens when autonomous systems move faster than human oversight can follow.
The same caution applies closer to home if you are experimenting with AI tools that write or deploy code on your behalf, sometimes called vibe coding. The risks there are similar in spirit: who controls the API keys, where does the data go, and what happens if something gets pushed live without proper review.
Retrieval-augmented generation: how AI reads your documents
Retrieval-augmented generation, or RAG, is how most enterprise AI tools work when they claim to ‘know’ your company’s data.
Rather than training a model from scratch on your internal documents, RAG systems retrieve relevant content from your files at the point of query and feed it into the model’s context window alongside your question. The model then generates a response grounded in that retrieved content rather than relying solely on what it learned during training.
For finance teams, this is practically significant. It is how a tool can answer questions about your specific expense policy, your supplier contracts, or your internal reporting standards, without those documents ever being used to train a shared model. The data retrieval happens within your environment; the model just processes what it is shown.
The distinction matters for data privacy reasons. A well-implemented RAG system gives you many of the productivity benefits of a general-purpose LLM while keeping sensitive documents out of the training pipeline.
It also means the model’s answers are traceable: you can see which document it pulled from, which makes auditing outputs more straightforward than interrogating a black-box model response.
RAG is not foolproof. The quality of the output depends heavily on how well the retrieval system finds the right content, and on how clearly your internal documents are written and structured. Garbage in, garbage out applies here as much as anywhere.
But as an approach for making AI useful on your organisation’s own data without the compliance risks of general-purpose tools, it is one of the more practical options available right now.
Model Context Protocol: giving AI tools to call
RAG solves how an AI model reads your documents. Model Context Protocol, or MCP, solves a related but different problem: how a model takes action, or pulls structured, live data from a specific system, rather than just retrieving a chunk of text.
Where RAG retrieves content and feeds it into a model’s context window, MCP exposes a defined set of tools that a model is allowed to call. A tool might fetch live data from a database, query a specific piece of software, or trigger a process elsewhere.
The model does not get free rein over a system; it can only call the tools it has been given, and only in the ways those tools allow.
This matters for finance because it is one of the building blocks behind the agentic workflows discussed above. An agent that reconciles transactions or flags a policy breach needs a way to actually reach into your systems, not just talk about them.
MCP is one of the more common ways that connection gets built today.
The same governance principle applies here as everywhere else in this article: scope matters. A well-built MCP tool only gives a model access to the data and actions a particular user is already entitled to use.
If you would not give a colleague unrestricted access to a system, you should not give an AI agent unrestricted access to it either, no matter how convenient that sounds in a demo.
We do not have an MCP server in Webexpenses yet. It is an early and fast-moving category, but worth understanding now, because it is likely to underpin a growing share of the agentic AI tools finance teams will be offered over the next year or two.
AI and expense fraud: a risk you should already be thinking about
One area where AI is not just useful but actively creating new risks is expense fraud. The same tools that make it easy to draft a report or summarise a document can generate convincing fake receipts in seconds.
Fake AI-generated receipts already accounted for around 14% of fraudulent documents submitted in 2025, compared to essentially nothing the year before.
This is a live and growing risk. If your expense management process still relies heavily on manual review of paper or image receipts, it is becoming harder to catch fraud at the point of submission.
The structural response is not careful looking at receipts. It is removing the opportunity by tying spend to verified transaction data. When an employee uses a corporate card, the transaction is confirmed by the card scheme, the payment processor, and the merchant before any receipt is ever submitted. There is no gap for a fake document to fill.
Where we stand on AI
We’re adding AI to our product, and we’ll keep gradually doing so. But only when it’s secure and when it genuinely benefits you. Not a moment before. The test is simple: will this actually add value for a finance team – or does it just make the product look more impressive in a demo?
AI auto-categorisation, for example, passes that test. It reduces manual effort, improves accuracy over time, and works quietly in the background without asking anything of the user. WADE passes it too: not because it replaces human support, but because it fills a specific gap our human teams cannot cover.
What we’re not doing is retrofitting AI into every corner of the product for the sake of it. The fundamentals still matter: an app that works simply and well, a support team made of actual people who know your account, and a process that gives your finance team visibility and control rather than another system to second-guess.
That question – will this add value? – is one worth applying to every AI tool you evaluate, not just ours. The category is moving fast and the marketing is moving faster. The finance teams that get the most out of AI in the next few years will be the ones that stay genuinely critical about what they adopt and why.
If you want to see how our AI auto-categorisation works in practice, we’re running a product roadmap webinar where we’ll be walking through this feature and what’s coming next. Register your place now.